SPI-t010 Admin menu
rev 05/18/2024 17:05
SECTIONS
SPI-t010 admin menu
rev 05/18/2024 17:05
|
SPI-0800.cfm rev 03/04/2024 12:16
SPORTS PAGE DOCUMENTATION
{ts '2026-04-06 22:53:14'}
0100: RUN THE SYSTEM
To Run the system:
http://www.mmcctech.com/sportspage
0200: SCRIPTS
Scripts are found on the server in:
/d/Websites/bcra-mlscom/mmcctech/SportsPage
0210: TOOLS
You can use: SPI_Space, SPI_Spacer, SPI_Spacer1, --- SPI_Spacer9
SPId_Space, SPId_Spacer, SPId_Spacer1, --- SPId_Spacer9
or #repeatString(" ",10)#
You can use: SPI_Space, SPI_Spacer, SPI_Spacer1, --- SPI_Spacer9
SPId_Space, SPId_Spacer, SPId_Spacer1, --- SPId_Spacer9
or
0300: mySQL DATABASE TABLES
Tables are stored in the MyBayCity.com database.
Sample query:
<cfquery name="SPIq_Stories" datasource="MyBayCity" >
SELECT * FROM mbc_tsportspage_idx
WHERE SPI_Type = 'P'
ORDER-BY SPI_IssueDate, SPI_Issue_Page
</cfquery>
0400: Raw data FOLDER and FILE EXAMPLES:
11/09/2023:
OJ Sent raw, scanned/OCR data to Josh.
Josh put the data on a thumb drive and sent to Stephen.
The data was in folders by type and year.
All of those folders have been uploaded to server folder
/d/Websites/bcra-mlscom/mmcctech/SportsPage
OCR-yyyy
Each folder contains each page of each issue.
The pages were scanned and converted to text via OCR.
OCR-1976
07-05-1976_THE-BAY-COUNTY-SPORTS-PAGEnn.txt pgs 1-16 FIRST issue on file.
07-19-1976_THE-BAY-COUNTY-SPORTS-PAGE01.txt pgs 1-16
etc.
OCR-1977
01-03-1977_THE-BAY-COUNTY-SPORTS-PAGE01.txt FIRST issue on file.
OCR-1978
01-02-1978_THE-BAY-COUNTY-SPORTS-PAGE01.txt FIRST issue on file.
05-05-1978_SPORTS-PAGE01.txt NEW filename format
OCR-1979
02-02-1979_SPORTS-PAGE01.txt FIRST issue on file.
OCR-1980
02-01-1980_SPORTS-PAGE01.txt FIRST issue on file.
OCR-1981
02-05-1981_ENTERPRISE01.txt FIRST issue on file.
another new filename format
OCR-1982
01-22-1982_ENTERPRISE01.txt FIRST issue on file.
OCR-1983
01-27-1983_ENTERPRISE01.txt FIRST issue on file.
OCR-1984
01-19-1984_ENTERPRISE01.txt FIRST issue on file.
10-18-1984_ENTERPRISE12.txt Final issue on file.
OCR-OJ-02-29-2024 DUPLICATE Data sent by OJ 2/29/2024.
VB_100_PL_yyyy
Each folder contains a JPG IMAGE of each page of each issue.
The filenames are consistent across all folders.
VB_100_PL_1976 PI_1976_07_05-PG01.jpg to PI_1976_12_20-PG20.jpg
VB_100_PL_1977 PI_1977_01_03-PG01.jpg to PI_1977_12_19-PG20.jpg
VB_100_PL_1978 PI_1978_01_02-PG01.jpg to PI_1978_12_29-PG16.jpg
VB_100_PL_1979 PI_1979_02_02-PG01.jpg to PI_1979_12_28-PG16.jpg
VB_100_PL_1980 PI_1980_02_01-PG01.jpg to PI_1980_12_31-PG20.jpg
VB_100_PL_1980-2 We can ignore this folder.
The files are all in the previous folder.
PI_1980_10_02-PGnn.jpg pages 1 to 16
PI_1980_10_09-PGnn.jpg pages 1 to 14
PI_1980_10_16-PGnn.jpg pages 1 to 14
PI_1980_10_23-PGnn.jpg pages 1 to 14
PI_1980_10_30-PGnn.jpg pages 1 to 14
PI_1980_11_06-PGnn.jpg pages 1 to 14
PI_1980_11_13-PGnn.jpg pages 1 to 14
PI_1980_11_20-PGnn.jpg pages 1 to 14
PI_1980_11_27-PGnn.jpg pages 1 to 14
PI_1980_12_04-PGnn.jpg pages 1 to 14
PI_1980_12_11-PGnn.jpg pages 1 to 14
PI_1980_12_18-PGnn.jpg pages 1 to 12
PI_1980_12_25-PGnn.jpg pages 1 to 12
PI_1980_12_31-PGnn.jpg pages 1 to 20
VB_100_PL_1981 PI_1981_02_05-PG01.jpg to PI_1981_12_31-PG08.jpg
VB_100_PL_1982 PI_1982_01_22-PG01.jpg to PI_1982_12_30-PG08.jpg
VB_100_PL_1983 PI_1983_01_27-PG01.jpg to PI_1983_12_29-PG24.jpg
VB_100_PL_1984 PI_1984_01_19-PG01.jpg to PI_1984_10_18-PG12.jpg
12/12/2023 There was confusion because some files were PI and some PL.
You cannot tell the difference between I and L in some screen fonts.
LOWERcase "ell" (l) and UPPERcase "eye" (I)
are rendered exactly the same in a sans serif font
Font_Family:
times ell: L l eye: I i
Arial ell: L l eye: I i
I fixed each folder named PI (eye) to actually be PL (ell).
The files all have PI prior to the year
EXCEPT for 1977, which has a PL in the name.
NOTE:
"760: DIR CONVERT (2023)"
in the main menu lets you see details from
any of the folders. You can also click on a file name and view that fils
via the browsser in a separate tab
The RAW data appears in the folders:
OCR_1976 241 files
12-20-1976_THE-BAY-COUNTY-SPORTS-PAGE01.txt 43
etc.
OCR_1977 500 files
12-20-1976_THE-BAY-COUNTY-SPORTS-PAGE01.txt 43
09-20-1977_THE-BAY-COUNTY-SPORTS-PAGE02 - Copy.txt 50
exception
etc.
OCR_1978 753 files
01-02-1978_THE-BAY-COUNTY-SPORTS-PAGE01.txt 43
Format changes at this issue:
05-05-1978_SPORTS-PAGE01.txt 28
etc.
OCR_1979 988 files
02-02-1979_SPORTS-PAGE01.txt 28
04-20-1979_SPORTS-PAGE_101.txt 30
exception pages 101 thru 112
OCR_1980 946 files
02-01-1980_SPORTS-PAGE01.txt 28
10-02-1980_BAY-CITY-ENTERPRISE01.txt 36
exception pages 10-02-1980 thru 12-25-1980
OCR_1981 592 files
02-05-1981_ENTERPRISE01.txt 27
12-10-1981_SPORTS01.txt 23
exception pages 12-10-1981_ thru 12-10-1981_SPORTS08
OCR_1982 597 files
01-22-1982_ENTERPRISE01.txt 27
OCR_1983 795 files
01-27-1983_ENTERPRISE01.txt 27
OCR_1984 845 files
01-19-1984_ENTERPRISE01.txt 27
total files: 6,257
| unique file name format |
page #
at |
name
LEN |
notes |
123456789.123456789.12
PI_1980_09_19-PG11.jpg
----------------^
|
17
| 22 |
IMAGE FILE |
123456789.123456789.123
12-10-1981_SPORTS01.txt
-----------------^
|
18 |
23 |
123456789.123456789.1234567
02-05-1981_ENTERPRISE01.txt
---------------------^
|
22 |
27 |
123456789.123456789.12345678
05-05-1978_SPORTS-PAGE01.txt
----------------------^
|
23 |
28 |
123456789.123456789.123456789.
04-20-1979_SPORTS-PAGE_101.txt
------------------------^
|
25 |
30 |
123456789.123456789.123456789.123456
10-02-1980_BAY-CITY-ENTERPRISE01.txt
------------------------------^
|
31 |
36 |
123456789.123456789.123456789.123456789.123
12-20-1976_THE-BAY-COUNTY-SPORTS-PAGE01.txt
-------------------------------------^
|
38 |
43 |
123456789.123456789.123456789.123456789.123456789.
09-20-1977_THE-BAY-COUNTY-SPORTS-PAGE02 - Copy.txt
-------------------------------------^
|
38 |
50 |
|
0600: Page image FOLDER and FILE EXAMPLES:
OJ Sent data to Josh.
Josh put the folders on a thumb drive.
All of folders have been uploaded to the
/d/Websites/bcra-mlscom/mmcctech/SportsPage server folder.
NOTE: "760: Parse DIR INFO" in the main menu lets you see details from
any of the folders. You can also click on a file name and view that fils
via the browsser in a separate tab
The PAGE IMAGE files appear in the folders:
VB_100_Pl_1976 237 files
PI_1976_07_05-PG01.jpg
etc.
VB_100_Pl_1977 497 files
PI_1978_01_03-PG01.jpg
etc.
VB_100_Pl_1978 753 files
PI_1977_01_03-PG01.jpg
etc.
VB_100_Pl_1979 991 files
PI_1979_02_02-PG01.jpg
etc.
VB_100_Pl_1980 767 files
PI_1980_02_01-PG01.jpg
etc.
VB_100_Pl_1980_2 237 files
PI_1980_10_02-PG01.jpg
etc.
VB_100_Pl_1981 593 files
PI_1981_02_05-PG01.jpg
etc.
VB_100_Pl_1982 597 files
PI_1982_01_22-PG01.jpg
etc.
VB_100_Pl_1983 787 files
PI_1983_01_27-PG01.jpg
etc.
VB_100_Pl_1984 845 files
PI_1984_01_19-PG01.jpg
etc.
|
0800: ENDING
1100: DATABASE
The primary data used by the Sports Page system is a single table in the
MyBayCity.com database.
This single table contains TWO types of records:
Type P
One record for every PAGE.
Type T
One record for every THUMBNAIL / CONTACT PAGE on the server.
Each record contains
Unique ID
Issue and the page number,
Type (P or T)
Text name of the issue
LINK
Type P link points to the Thumbnail / contact page image file, and the matching T record.
Type T link points to the URL where the issue is sold.
Data which is searched.
DataSource: MyBayCity
Table: mbc_tsportspage_idx
|
Lowest level of data -
One entry for each page from every issue.
|
| Fields |
|
| SPI_ProgramID |
Auto increment unique identifier to a page. |
| SPI_Type |
ONE byte text field indicating the record type:
P Single page with link to issue contact sheet.
T A single, 16-page issue description with link to where sold.
|
| SPI_Issue |
50 byte text field that is the name of the page |
| SPI_Link |
Link to the thumbnail image for the entire issue
Each page from the same issue points to the same ISSUE THUMBNAIL page.
Having the link associated with the page, any page COULD point somewhere else.
|
| SPI_Data |
"Text" block containing a summary of the page
This is generated from the page scan,
which is then read by an OCR-like processor.
|
1200: CLEANING UP RAW FILES
The raw data files with files made by scanning the printed pages to make files of some sort.
That process was done by a commercial service.
OJ then used OCR software to take those scans and convert them to plain text files.
He used 2 or 3 methods to do the various "generations" of conversions we've used.
The 2023 version was done about a year ago for Vickie to try to use.
When SGK got the files OJ wasn't sure how he had made them.
It was either "Notepad 2" or perhaps WORD.
Regardless of method, there were at least two formats. The first, which we experimented
with in 2021 and 2022, were HTML renditions. The conversion programs tried to identify
HTML patterns and clean those up. The cleaned data was then packed into a block and
that block was saved in the database in a large text field.
This method of just saving the text from an entire page works.
Our "search" algorythm uses the SQL "LIKE" operator to search. The query uses a constructed
query that reads:
WHERE SPI_Type = 'P' and SPI_Year = '1978' and SPI_Data like '%David LaPraire%'
That does not produce perfect searches, but it's very close.
The method used in 2023 is a pure text file. It does have a lot of special characters
embedded, but we just take most of them on face value and save in the database.
The "pure text" sometimes violates the MySQL database when updated from ColdFusion.
The Db operation will throw an error and not update the record.
Fortunately, the error messages shows about 50 characters in the area of the problem
and that's enough to find the error using notepad.
Our methods is this:
- OJ runs the SPI-0760.cfm script. It shows a list of all the raw files.
Each has an UPDATE and a VIEW button.
Clicking the UPDATE reads the raw data file for one page of an issue.
It combines all the data lines into a large block and updates the database.
- When the data offends MySQL's ColdFusion update, the original raw file needs
to be cleaned up so it works.
- We first download the bad raw file to the local machine appending "-ORIG" to the
file name. This is just so we can keep an original copy handy.
Next we open that ORIG file in Notepad. We look at the MySQL update error
show in SPI-0760.cfm and pick a few letters from the error message.
Using Notepad's CTRL-F (find) function we search the file for that offending string.
When we find it we just select and delete all of the special characters that,
inevitably, surround it.
Note that we'll usually clean out some of the other "special character" code
that we find in the file. We don't need to, but as long as we're there
we might as well get rid of it.
We SAVE AS removing the ORIG so that we have a new file with the standard
filename.
Leaving all the stuff open, we Ftp that repaired file back to the web server.
We use the UPDATE button in SPI-0760 again to convert the file.
If there are more errors we just repeat the fix. If the convert works,
we're done.
1300: HOW THE OCR WORKS
 Based on use, we've deduced how the current OCF conversion operates.
Basically it takes the scan snd works left to right, top to bottom.
Based on use, we've deduced how the current OCF conversion operates.
Basically it takes the scan snd works left to right, top to bottom.
(Note that the HTML OCR conversion seemed to try to make a page
that actually worked and duplicated the page. It was not perfect,
but it did a fair job. But we never used the HTML code to try
to produce the pages.)
This method works, well enough, but it does not produce a file that can be
easily read. The newspaper is typically printed in columns with display
ads included.
The results of this can be a challenge to read. You may get some text from
column1, some from colum 2, 3, and 4. Then theres a break and you get more
from those same columns.
To confound the problems, there may be different fonts and different size fonts.
Lines may not "line up".
There can be pictures almost anywhere. Some pictures will include captions.
And then there are the display ads. Those can be any size and any
orientation. They can include images of their own and multiple fonts too.
It's best to just not worry about these issues. The objective of the
Sports Page search program is just to identify which pages contain
a search string. We don't care where the words are. We just want to
sell the entire page.
2100: WHAT's FOR SALE
It was not entirely clear exactly what will be sold.
The plan has evolved and as of Jan 2024,
It is understood that we will sell one Kindle book for
each issue (normally 16 pages).
A secondary format would be the same type of book prepared and
printed by Thumb Printing in Bay City.
A scaned issue of every page of each issue is on the web site.
When a customer makes a search,
a table will be shown of every page containing the search results.
The table will include a link to purchase the Full book for each collection
of pages.
Following the table, ALL of the pages will be shown.
The page image is large enough to understand but not to actually read.
Blowing the image up will begin to pixelate the image.
OLD NOTES:
A single image (JPG) "contact sheet" containing thumbnail sized images of each
of the 16 pages in that issue will be stored on the server.
A description of that image will be found in the database as record type "T".
That contact sheet image entry will include a link pointing
to wherever that issue is sold.
(For testing, they all point to Kent's "James Milton" book.)
SO... let's says that the name "Steve" appears on four individual pages.
Two of those pages are in the 7/5/76 issue and two are in the 7/19/76 issue.
Following the search the system will show a table of the four references
and the page and issue the reference appears in.
Following that table of references the system will show the contact sheet image
for each of the two issues.
Each contact page image will be a link, which will to to the internet address
where the "book" of that issue can be purchased.
The customer will click the link of the issue/book they want and
make the purchase.
2200: SALE
We sell one BOOK for each issue.
An issue typically has 14 to 16 pages. So the associated book has that many pages.
Most pages were printed in a larger, newspaper format.
These had the 14 to 16 pages.
Another group was printed in 8.5 x 11 inch books.
Each page was smaller to there were many more pages for each issue.
The book sales link will not distinguish the different styles.
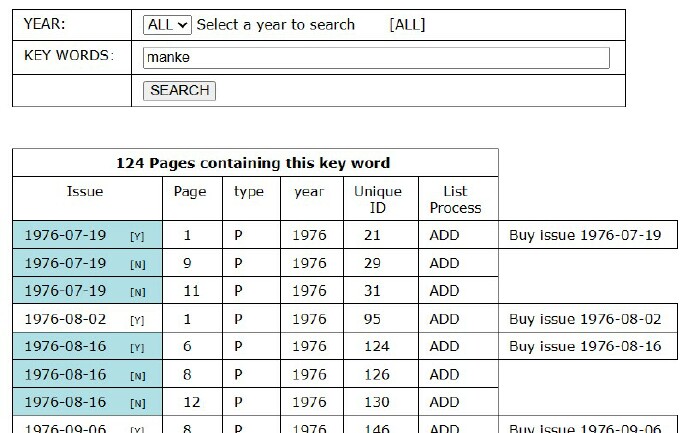
2300: SEARCH
The SEARCH asks the user select a year and enter a search key.
The year originally offered the option to search a single year.
That was thought to be necessary due to the time required for
a full search.
After testing it was found that the full search of every page
for every year was fast enough.
The YEAR list was left in the program, but it only offers
an option for ALL years. When we're sure it works we'll
remove the YEAR option.
The key word is a single string.
If the customer enteres "JOHN JONES" that exact string will be found.
Letter case is not significant. John is the same as JOHN and john.
Warning... the original scan of the page was submitted to an OCR program
which changed it to text. There may be cases where a name or phrase
was split across 2 lines. If that happened with a case of "john jones",
the reference may not be found because there would be a page break
between the two name pargs.
The results of the search will be shown in a table including the
issue date and the page number.
A "Buy" button will be provided for the FIRST link for the book.
That is, if there are 3 hits in the same book (see example below)
a "Buy" only shows on the FIRST hit for the book.
2400: KINDLE CODES
The KINDLE book requires a unique identifier for each book.
We need a place to keep that code.
The database has an entry for every page in every issue.
We put the associated KINDLE CODE on those records for each issue.
If there are 14 pages for a specific issue,
The program presents a single link where you can enter
that code for the entire book.
When you click the "UPDATE-KINDLE" button, the code
is automatically stored on every page record for that issue.
UPDATE PROGRAM:
A link in the menu shows
780: Update Amazon/Kindle codes
The 780 program initially just shows a list of YEAR buttons.
When you click on one of those buttons the screen will reload
and show that table of issues for that book.
Once you select a year, you will see that list of pages for the issue.
The FIRST line shows the issue year-month-day followed by all of the page numbers.
(If you hover the mouse over a page number, a tooltip will show some details.)
The SECOND line will ask you to enter kindle book code then click an "UPDATE-KINDLE" button.
(To the right are some details about the page as well as the current value of the
kindle code for the first page.)
After you run the "UPDATE-KINDLE", the list will show the code that you entered on the
particular page. You can also check the info to the right and see the code for the first page.
To update another page just enter it's code and click the "UPDATE-KINDLE".
The returned screen will only show the last code that you did.
You just enter the next code and click its button.
The button only updates the one line that it appears on.
If you leave the previous code it will be ignored.
3100: METHODS
How can I read a simple text file, processing each line of the file?
ColdFusion makes it easy to read a file using the <cfloop> tag.
By using the file attribute,
you can tell <cfloop> to iterate over each line of a file.
This sample reads in a text file and displays each line:
<cfset myfile = expandPath("./dump.txt")>
<cfloop index="line" file="#myfile#">
<cfoutput>
The current line is #line#
</cfoutput>
</cfloop>
This question was written by Hal Helms
It was last updated on July 1, 2008.
Found at:
https://www.coldfusioncookbook.com/entries/How-can-I-read-a-simple-text-file-processing-each-line-of-the-file.html
9900: ENDING
End right column, row and table (in t900 rev 03/30/2024 16:16 )
|